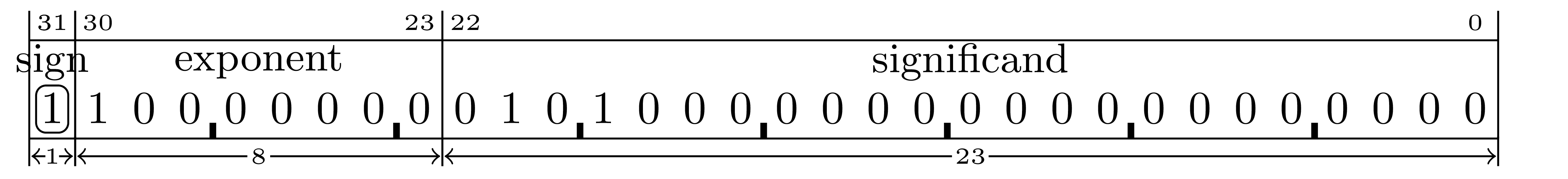The ‘.’ in a binary number is a binary point, not a decimal point.
We use scientific notation as in \(2.7 \times 10^{-47}\) to express either small fractions or large numbers when we
are not concerned every last digit needed to represent the entire, exact, value of a
number.
The format of a number in scientific notation is \(mantissa \times base^{exponent}\)
In binary we have \(mantissa \times 2^{exponent}\)
IEEE-754 format requires binary numbers to be normalized to \(1.significand \times 2^{exponent}\) where the significand is the
portion of the mantissa that is to the right of the binary-point.
The unnormalized binary value of \(-2.625\) is \(-10.101\)
The normalized value of \(-2.625\) is \(-1.0101 \times 2^1\)
We need not store the ‘1.’ part because all normalized floating point numbers will start that
way. Thus we can save memory when storing normalized values by inserting a ‘1.’ to the left of
significand.
When the exponent is all ones, the significand is all zeros, and the sign is zero, the number
represents positive infinity.
When the exponent is all ones, the significand is all zeros, and the sign is one, the number
represents negative infinity.
Observe that the binary representation of a pair of IEEE-754 numbers (when one or both are
positive) can be compared for magnitude by treating them as if they are two’s complement
signed integers. This is because an IEEE number is stored in signed magnitude format
and therefore positive floating point values will grow upward and downward in the
same fashion as for unsigned integers and that since negative floating point values
will have its MSB set, they will ‘appear‘ to be less than a positive floating point
value.
When comparing two negative IEEE float values by treating them both as two’s complement
signed integers, the order will be reversed because IEEE float values with larger (that is,
increasingly negative) magnitudes will appear to decrease in value when interpreted as signed
integers.
This works this way because excess notation is used in the format of the
exponent and why the significand’s sign bit is located on the left of the
exponent.1
Note that zero is a special case number. Recall that a normalized number has an implied 1-bit
to the left of the significand… which means that there is no way to represent zero! Zero is
represented by an exponent of all-zeros and a significand of all-zeros. This definition allows
for a positive and a negative zero if we observe that the sign can be either 1 or
0.
On the number-line, numbers between zero and the smallest fraction in either direction are in
the underflow areas.
On the number line, numbers greater than the mantissa of all-ones and the largest exponent
allowed are in the overflow areas.
Note that numbers have a higher resolution on the number line when the exponent is
smaller.
The largest and smallest possible exponent values are reserved to represent things requiring
special cases. For example, the infinities, values representing “not a number” (such as the result
of dividing by zero), and for a way to represent values that are not normalized. For more
information on special cases see [?].
B.1.1 Floating Point Number Accuracy
Due to the finite number of bits used to store the value of a floating point number, it is not possible
to represent every one of the infinite values on the real number line. The following C programs
illustrate this point.
B.1.1.1 Powers Of Two
Just like the integer numbers, the powers of two that have bits to represent them can be represented
perfectly… as can their sums (provided that the significand requires no more than 23
bits.)
When dealing with decimal values, you will find that they don’t map simply into binary floating
point values.
Note how the decimal numbers are not accurately represented as they get larger. The decimal
number on line 10 of subsubsection B.4 can be perfectly represented in IEEE format.
However, a problem arises in the 11Th loop iteration. It is due to the fact that the binary
number can not be represented accurately in IEEE format. Its least significant bits were
truncated in a best-effort attempt at rounding the value off in order to fit the value into
the bits provided. This is an example of low order truncation. Once this happens, the
value of x.f is no longer as precise as it could be given more bits in which to save its
value.
These rounding errors can be exaggerated when the number we multiply the x.f
value by is, itself, something that can not be accurately represented in IEEE
form.2
For example, if we multiply our x.f value by \(\frac {1}{10}\) each time, we can never be accurate and we start
accumulating errors immediately.
In order to use floating point numbers in a program without causing excessive rounding
problems an algorithm can be redesigned such that the accumulation is eliminated. This
example is similar to the previous one, but this time we recalculate the desired value from a
known-accurate integer value. Some rounding errors remain present, but they can not
accumulate.
1I know this is true and was done on purpose because Bill Cody, chairman of IEEE committee P754 that designedthe IEEE-754 standard, told me so personally circa 1991.
2Applications requiring accurate decimal values, such as financial accounting systems, can use a packed-decimalnumeric format to avoid unexpected oddities caused by the use of binary numbers.